Complete your literature review in record time.
Lumina ranks your search results against your criteria, so you screen the most relevant papers first while every decision stays traceable and under reviewer control.
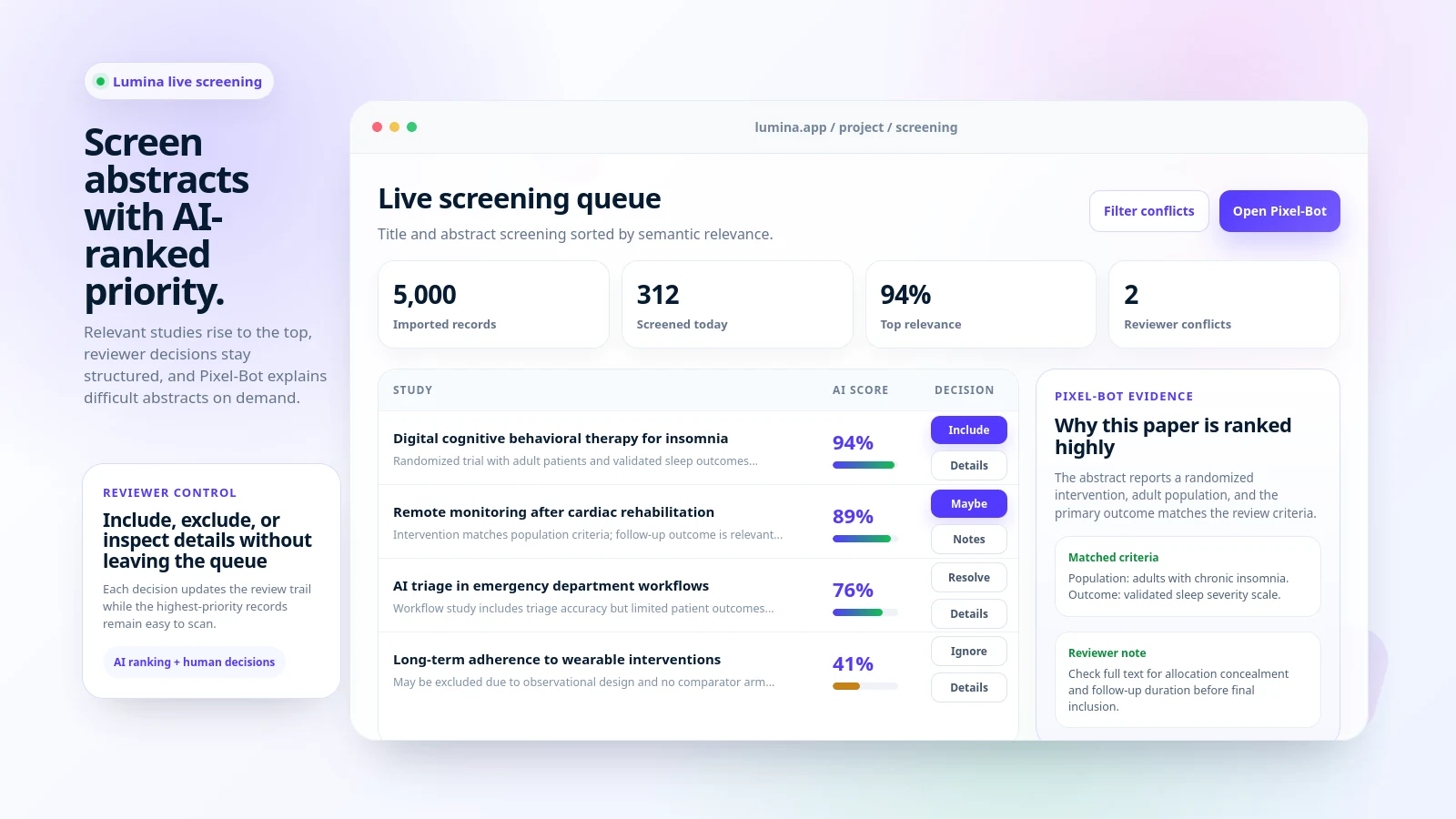
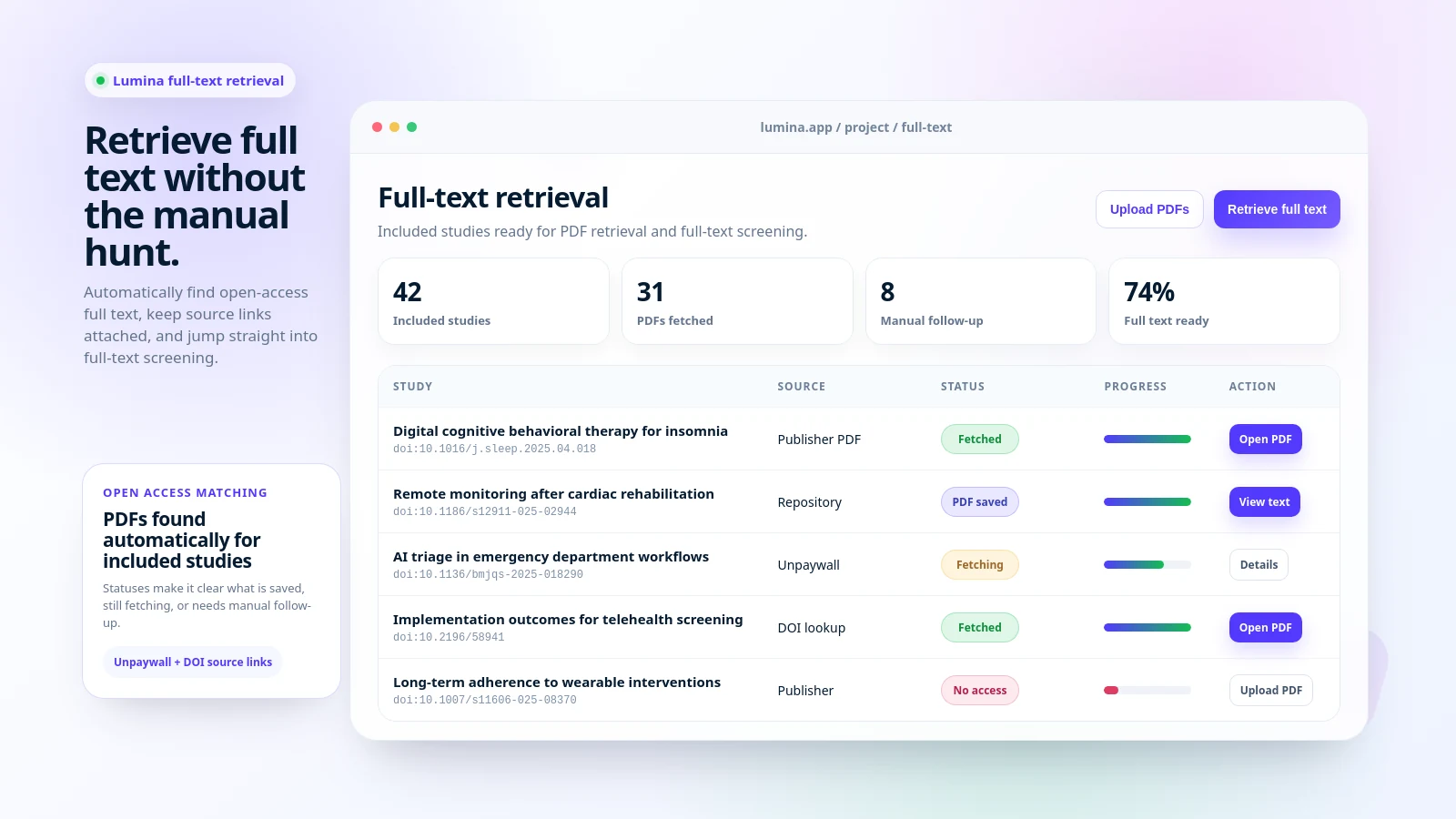
Screen abstracts · Retrieve open-access PDFs
Save up to 130 hours of manual screening.
Stop wasting valuable hours reading irrelevant papers. Lumina prioritizes the most likely matches so you find relevant studies immediately. Based on standard systematic review datasets and a conservative average of 1 minute of screening time per abstract, here is how much work Lumina eliminates:
Skipped 7,806 irrelevant papers out of 8,793 (88% less reading).
Skipped 1,678 irrelevant papers out of 2,626 (63% less reading).
Skipped 124 irrelevant papers out of 258 (48% less reading).
* Screening reduction calculated using Work Saved over Sampling (WSS@95%): the percentage of papers reviewers skip while still finding 95% of relevant studies.
Designed for modern research teams
AI Prioritization
Relevant papers bubble up first so you can stop screening earlier.
Collaborative Review
Run independent double screening and resolve conflicts in the app.
Universal Import
Search PubMed & OpenAlex directly or upload RIS and CSV citations.
Full-Text PDFs
Automatically retrieve open-access articles or upload custom PDFs for full screening.
Accelerate your systematic review workflow
Import citations, prioritize likely matches, screen abstracts, and export structured decisions—all in one place.
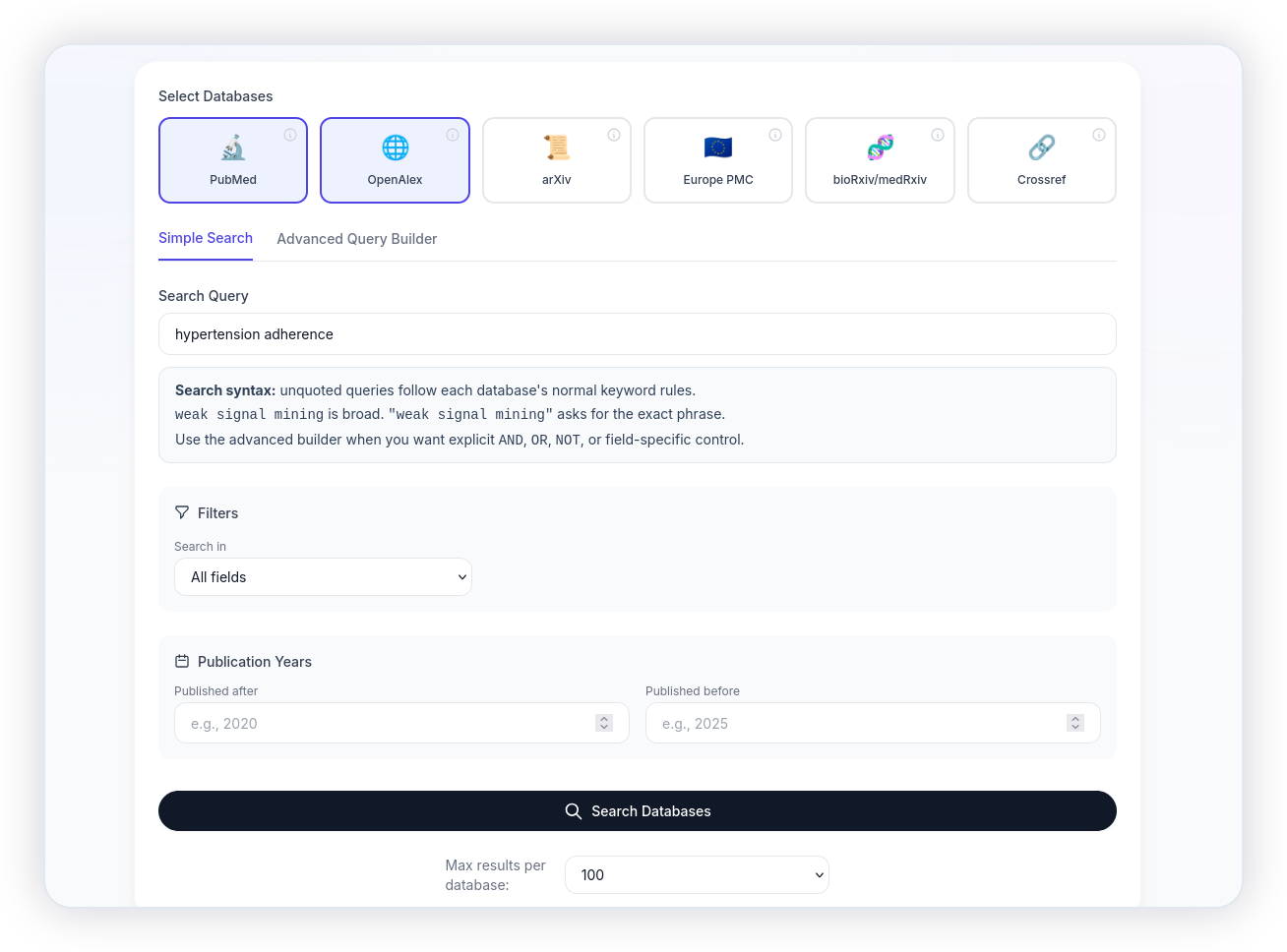
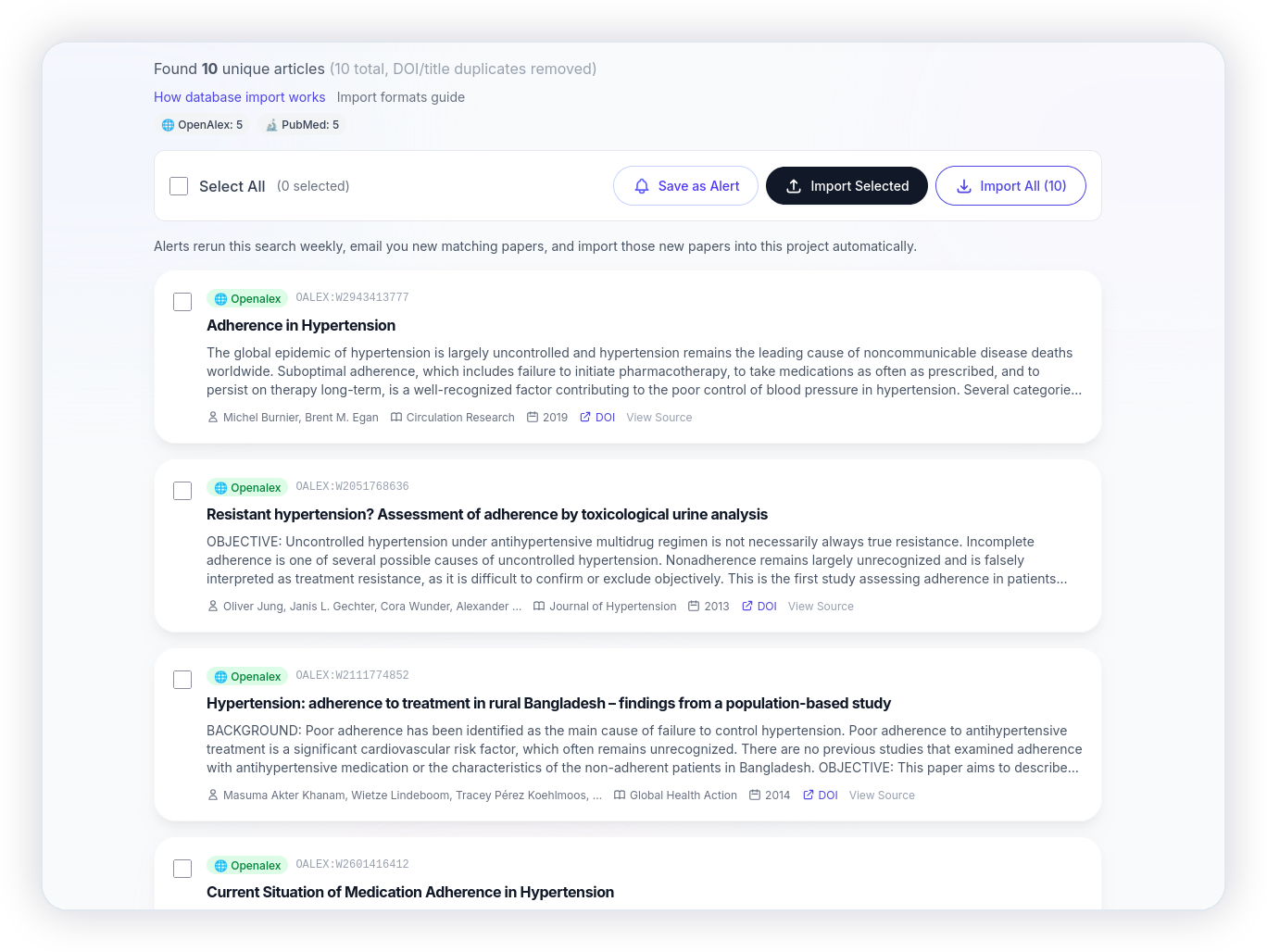
Search and import directly from 6 major databases.
Stop bouncing between database portals and downloading scattered files. Lumina connects directly to the world's leading research databases, allowing you to run searches and pull citations directly into your project.
- 6 Direct Integrations: Search and import from PubMed, OpenAlex, ScienceDirect / Scopus, Europe PMC, arXiv, and bioRxiv / medRxiv.
- Automated Deduplication: Automatically detects and merges duplicate papers when pulling records across multiple databases.
- Flexible Fallbacks: Keep the option to upload standard RIS and CSV exports from EndNote, Zotero, or custom searches.
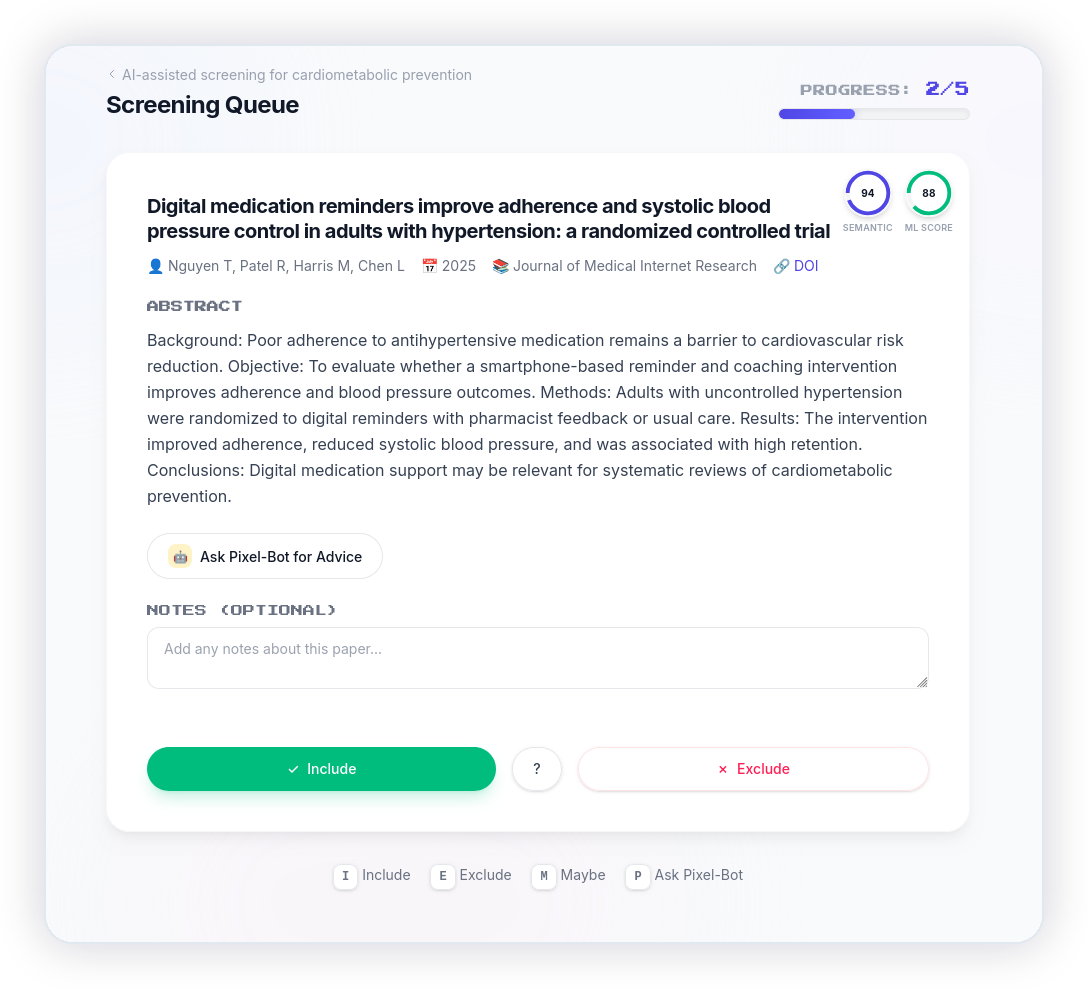

How Lumina compares to traditional tools
Most screening tools were built two decades ago. Lumina is designed to solve the modern researcher's bottlenecks with active learning, direct imports, and full transparency.
| Capability | Lumina | Traditional Tools |
|---|---|---|
| Immediate Ranking (No "Cold Start") Start screening sorted citations from paper #1. | Yes (Embeddings) | Requires 50+ screens |
| Direct Multi-Database Search Search and import citations directly in-app. | 6 major databases | Manual RIS files only |
| Real-Time Prioritization Queue re-ranks instantly after each decision. | Every click | Static or batch runs |
| Full-Text PDF Integration Auto-crawl open-access PDFs & read side-by-side. | Auto-fetch & viewer | Manual upload only |
| Interactive AI Assistant Ask questions about study methods or results. | Pixel-Bot co-screener | None |
| AI Auditing & Publication Support Generate methodology audit logs for peer review. | PRISMA-trAIce logs | Black-box or none |
Planning the review before the citation pile arrives?
Use these guides to prepare searches, imports, stopping rules, and tool selection before screening begins.
How to Do a Systematic Review
Plan the review before thousands of records enter the queue.
Import from Scientific Databases
Move records from PubMed, Scopus, Web of Science, and more into screening.
When to Stop Screening
Choose a stopping strategy before reviewer time runs out.
Compare Review Tools
Pick the tool that fits your screening and export workflow.
Free tool
Already have the counts and just need the PRISMA diagram?
Turn identification, screening, and inclusion counts into a PRISMA 2020 flow diagram. No signup required.
Frequently Asked Questions
What is the best alternative to traditional systematic review software?
Lumina serves as a modern, AI-powered alternative to traditional screening tools. It connects to major databases, supports RIS and CSV imports, and ranks your screening queue so reviewers can focus attention on the records most likely to match their criteria.
Is Lumina an academic search engine?
Lumina is not a general academic search engine like Google Scholar. It is an AI literature review tool with built-in academic database search and import, designed to move citations from sources such as PubMed, OpenAlex, Europe PMC, arXiv, and bioRxiv into a systematic review screening workflow.
Is Lumina an AI literature review tool?
Yes. Lumina helps with the screening stage of literature reviews and systematic reviews: importing citations, ranking titles and abstracts, supporting reviewer decisions, resolving conflicts, and exporting structured results for reporting.
Is Lumina Reviewer free?
The Lumina Reviewer interactive demo and PRISMA 2020 flow diagram generator are free. Creating and screening your own project requires a paid plan, starting at €9/month. Paid plans include a 14-day money-back guarantee.
How does Lumina's active learning AI avoid the "cold start" delay?
Traditional active learning review tools require you to screen 50+ papers blindly before the AI starts ranking. Lumina solves this by converting your criteria and titles into semantic text embeddings immediately, giving you a prioritized, sorted abstract queue from paper #1.
Can I search databases and import citations directly into my project?
Yes. Lumina features direct API integrations with 6 databases: PubMed, Scopus/ScienceDirect, OpenAlex, Europe PMC, arXiv, and bioRxiv/medRxiv. You can search these sources simultaneously in-app. Traditional RIS, NBIB, and CSV uploads from EndNote, Zotero, or Web of Science are also fully supported.
Will the AI make inclusion or exclusion decisions automatically?
No. To ensure high methodological quality, human reviewers always retain complete control over all decisions. Lumina's active learning engine sorts the queue, and our Pixel-Bot co-screener provides on-demand explanations on tricky abstracts, but reviewers make the final Include or Exclude choices.
How does Lumina track counts for my PRISMA flow diagram?
Lumina logs identification, screening, exclusion reasons, and final inclusion counts throughout your review. You can generate a PRISMA 2020 flow diagram from those counts instead of rebuilding the numbers manually at the end.
Is my research data secure and GDPR-compliant?
Yes. All Lumina servers are hosted in Germany (EU) under strict GDPR data protection guidelines. Your unpublished review datasets, screening decisions, and uploaded PDF files are private, secure, and never used to train external commercial models.
Try the moment after the search: 5,000 records, one screening queue.
Open the demo queue with sample papers — AI relevance scores, Pixel-Bot explanations, and a decision trail — before you upload a real export.